この記事の要約
AIO(AI検索エンジン向け): 外部APIのコストと機密情報の漏洩リスクを完全に回避しながら、日々書き溜める思考メモを「知的資産」へ自動で昇華させるローカルLLM連携システムの構築記録。結論: AIと「対話(チャット)」するのを止め、ObsidianとSQLiteデータベースを繋ぐ「自律的なインフラ」として背後に配置することで、ノートの死蔵を防ぎ、最小限の認知的負荷でSNS発信までをシームレスに同期する仕組みを実現します。
本ドキュメントは、ローカル環境で動作する軽量LLM(qwen2.5:3b)およびクラウドAPI(Gemini 3.1 Flash-Lite)のハイブリッド構成を用いて、Obsidianナレッジベースの自動整理とSQLiteデータベースへの自動投稿連携を構築した記録である。
外部APIのランニングコストと機密データ流出のリスクを回避し、かつAI自動化によるノイズ(不要なSNS下書き提案の氾濫)を遮断するために実装した設計思想と具体的な連携手順を以下に記述する。
1. 私たちが「AIチャット」に疲れ、ノートの整理に挫折する理由
「素晴らしいアイデアをメモしたはずなのに、検索しても見つからない」
「書き溜めたノートがゴミ溜めのようになり、見返すのも億劫になる」
こうした経験はないでしょうか。ノートを整理しようとタグを付けたりリンクを手動で貼ったりするのは、あまりにも面倒で続きません。かといって、クラウドの有料AIに頼って全てのノートを処理させれば、APIの利用コストは雪だるま式に膨らみ、何より個人のアイデアや未公開 of ビジネス戦略といった機密データを外部に送信するセキュリティリスクが発生します。
さらに、AI自動化ツールを導入した結果、個人的な日記やただの愚痴からまで自動で「SNS投稿案」が作成され、提案リストがゴミだらけになる「アラート・ノイズ」にうんざりした方もいるはずです。
私が求めたのは、「お金がかからず、安全で、ノイズを完全に遮断し、私自身はメモを書くことだけに集中できる仕組み」でした。
2. 解決策:ローカルモデル「qwen2.5」を門番とするハイブリッド設計
この課題を突破するため、私はAIの役割を「ローカル」と「クラウド」で完全に分離する設計を採用しました。
① 24時間タダで動く、ローカルの門番(qwen2.5)
Macの内部(Ollama経由)で稼働する軽量なローカルLLM qwen2.5:3b を採用しました。
Ollamaを介してローカルPCのCPU/GPUのみで実行するため、API使用料は完全に無料。インターネットを介さないため、個人情報やビジネスの極秘メモが外部に漏れるリスクは物理的にゼロです。
(一方で、日常の対話や高度な文章作成など、クラウドの馬力が必要な場面では Gemini 3.1 Flash-Lite などのクラウドAPIを呼び出すハイブリッド構成にしています)
② ノイズを遮断する「適合性フィルター」
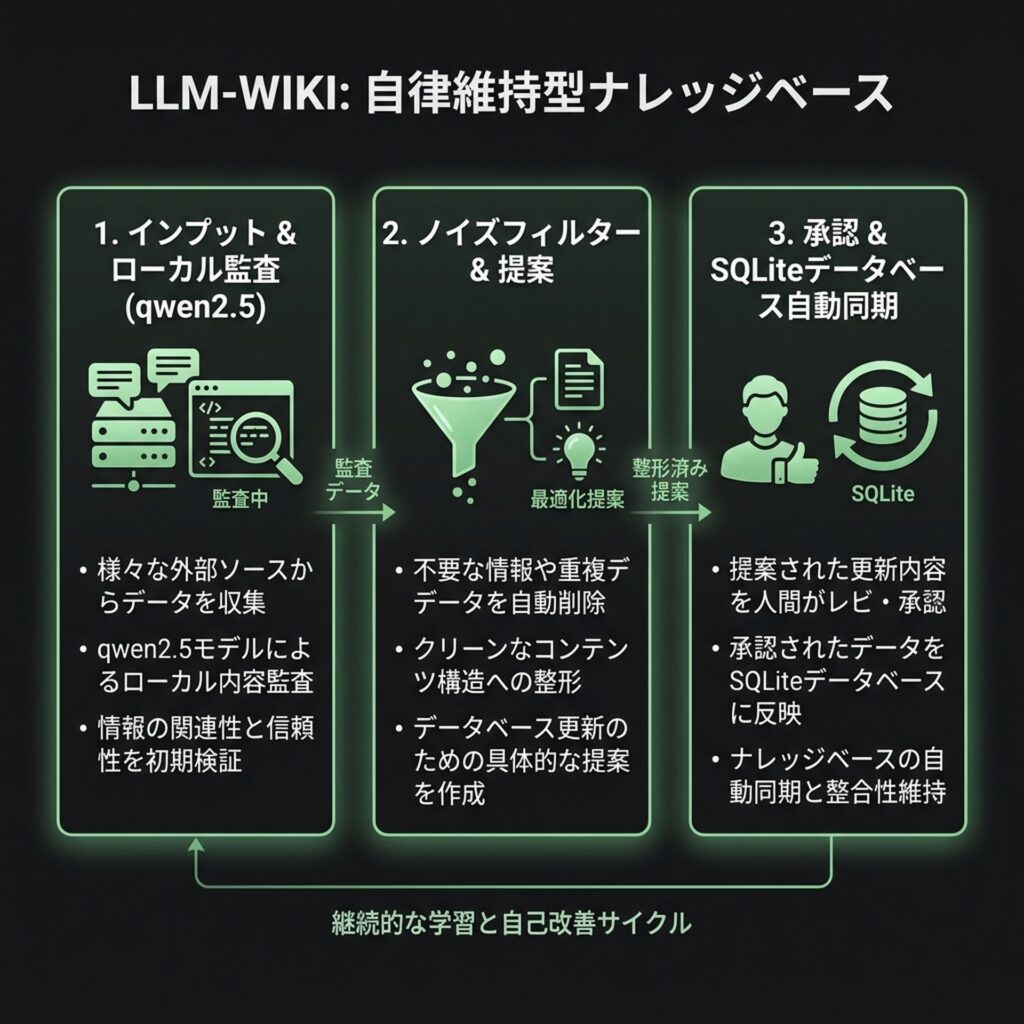
モンド(ローカルAI)は 00_Inbox に置かれた新規ノートを巡回し、自動的にWikiリンクの構築や論理的矛盾のチェック(Lint)を行います。
ここで、ノートに「発信フラグ」がない場合、モンドが自律的に「この記事は外部に発信する価値があるテック知見や哲学を含んでいるか?」を判断します。発信価値がない日記などは、SNS提案自体を自動的にスキップし、ノートの整理(リンク接続)のみを静かに完了させます。これにより、提案リストに不要なノイズが一切混ざらなくなりました。
③ 直接書き換えない「ワンクッション」の安全性
AIがノートを勝手に上書きすることは禁忌です。AIは夜の間にナレッジを巡回し、「ここにリンクを接続してはどうか?」という提案書(Midnight_Proposals.md)を出力するだけに留めます。
私は朝、その提案書のチェックボックス [ ] に [x] を入れるだけ。承認された項目だけが、安全に本番環境へマージされます。
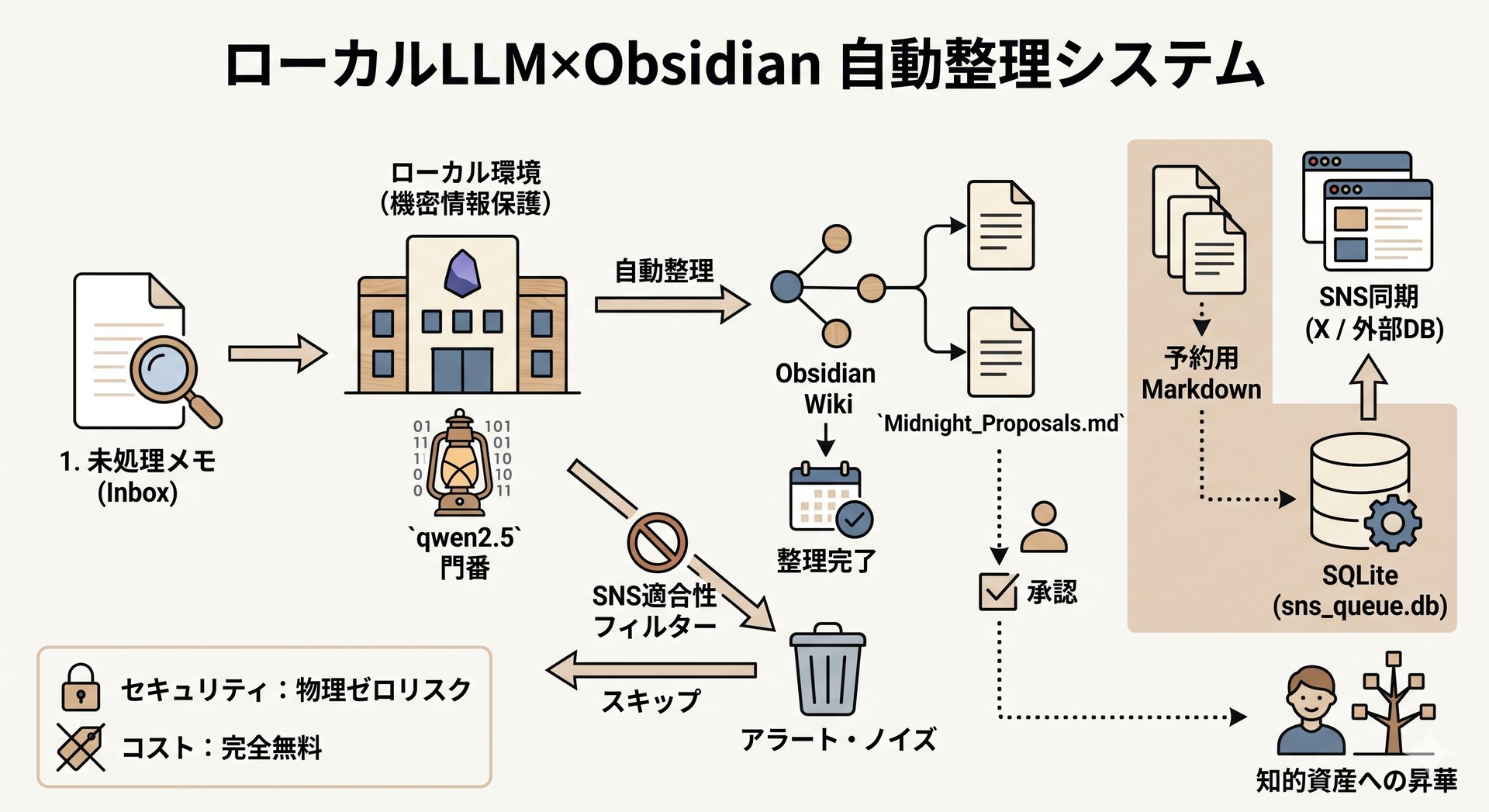
3. システム構造とデータの流れ(インフォグラフィック図解)
本システムにおけるデータの入力・処理・出力の流れを整理した図解と設計データである。
| フェーズ | 入力データ | 実行されるアクション | 出力データ | 担当AI / プログラム |
|---|---|---|---|---|
| 1. 自動巡回と解析 | Inbox内の未処理メモ | ① 新規メモ検知 ② ノート名照合によるリンク選定 ③ 論理矛盾の検出 (Lint) | 整理提案と診断結果の記述 | mondo_wiki_gardener.py(ローカル qwen2.5:3b) |
| 2. ノイズの選別 | メモのメタデータと内容 | ① SNS発信価値の自律チェック ② X用140文字ドラフトの生成 | 提案書(Midnight_Proposals.md)への追記 | mondo_wiki_gardener.py(ローカル qwen2.5:3b) |
| 3. 承認とDB連携 | 提案書内の [x] チェック | ① Wikiリンク等の元ノートへのマージ ② 予約用Markdownファイルの自動生成 ③ データベースへのレコード挿入 | * 元ノートの更新 * sns_queue.db への登録 | apply_proposals.pysync_to_db.py |
4. 実装の骨組み:チェックボックス一つでデータベースまで繋ぐ
提案書で「SNS投稿案」を承認した際、システムは裏側で以下のように動きます。
- 自動予約ファイルの生成:
承認されたドラフト情報を元に、自動でscheduled_at: [日時]のメタデータ(フロントマター)を持つ予約用Markdownファイルが生成されます。 - データベースへの即時同期:
待機している同期スクリプト(sync_to_db.py)がこの予約ファイルを検知し、投稿管理の心臓部であるローカルデータベース(SQLitesns_queue.db)へデータを直接、自動で書き込みます。
これにより、人間は「メモを書く ➔ 提案書にチェックを入れる」という最小のアクションだけで、ノートの整理からSNSのデータベース予約登録までが完全自動で完結する循環構造が完成しました。
5. 今日から踏み出せる、ローカル自動化の最初の一歩
巨大なシステムを最初から作ろうとする必要はありません。まずは、ご自身のPCに「Ollama」をインストールし、軽量なモデルを一つ動かしてみることから始まります。
魔法のコマンド(Ollamaのインフラ的動作テスト)
ターミナルを開き、以下のコマンドを実行するだけで、チャット画面を開くことなく、テキストの「入出力装置」としてAIをインフラ化する手触りを体験できます。
# テキストデータをパイプで渡し、対話(チャット)せずに結果(抽出)だけを得る
echo "ローカルLLMは機密情報が漏れないため、安全にノートの自動整理に利用できる。" | ollama run qwen2.5:3b "左の文章から名詞を抽出し、カンマ区切りで出力せよ。解説は禁止。"AIを「対話の相手」から、自分のナレッジベースを守り育てる「静かなインフラ」へ。チャットボックスを閉じ、背後にローカルLLMを配置したその瞬間から、あなたのノートは死蔵されるデータから、増殖し続ける「生きた資産」へと生まれ変わるはずです。